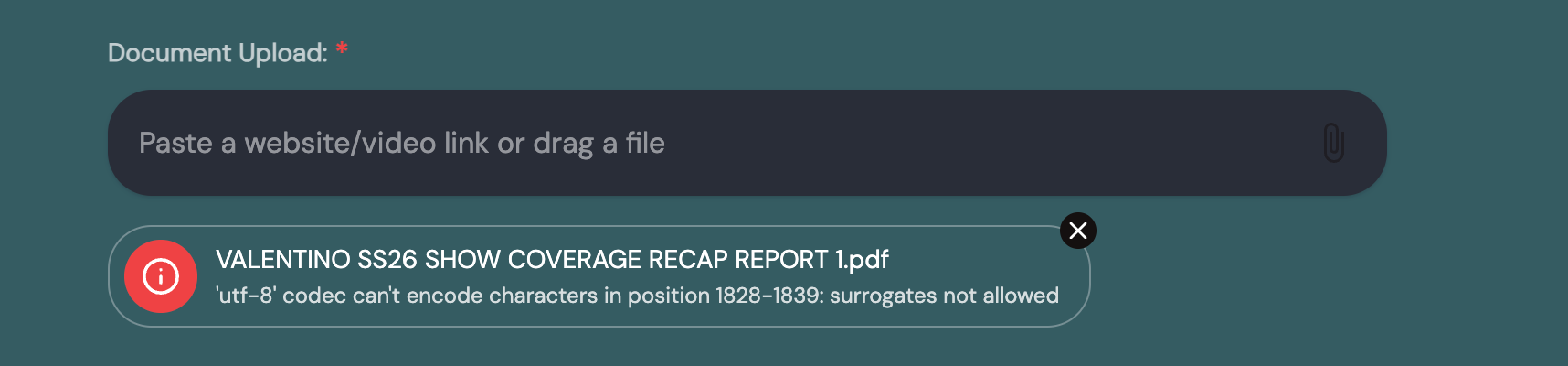
We’ve recently encountered an error when uploading a particular PDF. Anyone who uploads this PDF gets the same error. Other PDFs are fine. Can anyone shed some light? We’re using Pickaxe for users to upload these files and we’ll then port them over to n8n for other works, so it’s important it’s able to read all PDF files. Thanks!
The file can be downloaded here.
Could the error be because there are Thai characters in it?
Hi @james.yeoh ,
The issue you are seeing is not caused by the presence of Thai characters. Thai and other non-Latin scripts are fully supported by UTF-8 encoding, which Pickaxe uses. The problem appears to come from how the PDF was originally generated. The internal text layer of the document contains invalid or corrupted font-to-Unicode mappings, which means some characters cannot be properly interpreted as valid UTF-8 text.
This usually happens when the PDF embeds fonts that use non-standard encoding or when the export process from the source software produces a malformed text layer, even if the document appears normal visually.
To fix this, try re-exporting or re-saving the PDF from the original software using the “Save as PDF/A” or “Print to PDF” options. To help us better understand the cause, could you please let us know which tool or software was used to create or export this PDF? Also, if you happen to know whether the original file included custom fonts or was exported from a non-English language setting, that information would be very helpful.
Hi Danny,
Thanks for the reply and explanation. I tried this file directly on n8n and it was able to process everything. I cannot control what my users decide to do with their files, but our backend tool can handle this, and we prefer to use Pickaxe as the front, it’ll be good that Pickaxe can just accept the file and pass it on via webhook like what we expect it to do. So since Pickaxe is acting as a fetch and dispatch here, can it ignore the error and do just that?
Hi James,
Pickaxe saves both the original uploaded PDF and a generated .txt file that contains the extracted text. When a user uploads a document, the system attempts to extract readable text for downstream use. Both file types are available programmatically through environment variables:
PICKAXE_END_USER_DOC_URLS gives you the original PDF file URLs.PICKAXE_END_USER_RAW_DOC_URLS provides URLs for the extracted .txt versions.
In your case, the issue arises because the uploaded PDF is corrupted, which prevents the system from generating the .txt file. Since text extraction fails, the upload process halts instead of passing the file along.
The behavior you’re seeing is just the platform’s safeguard against unreadable or malformed documents. If you re-export the same PDF using a clean method, it will upload successfully, and you’ll be able to pass it to n8n via webhook as expected.
So yes, what you’re trying to do is fully possible, but it requires a valid PDF that can be parsed into text. Once the file is structurally sound, both the original and the text version will be available for your automations.